Merhaba, bu yazımda sizlere Proxmox VE üzerinde Ceph Storage kurulumunu anlatıyor olacağım.
Öncelikle Proxmox VE üzerine Ceph kurulumumuzu ve ayarlarımızı yapmadan önce Ceph’in yapısından ve mimarisinden başlayalım.
Ceph kurulumlarında sıkca duyacağımız PG (Placement Group), OSD (Object Storage Daemon), RBD (Rados Block Device), Ceph MON ve Ceph MGR terimlerini inceleyelim.
Ceph Mimarisi
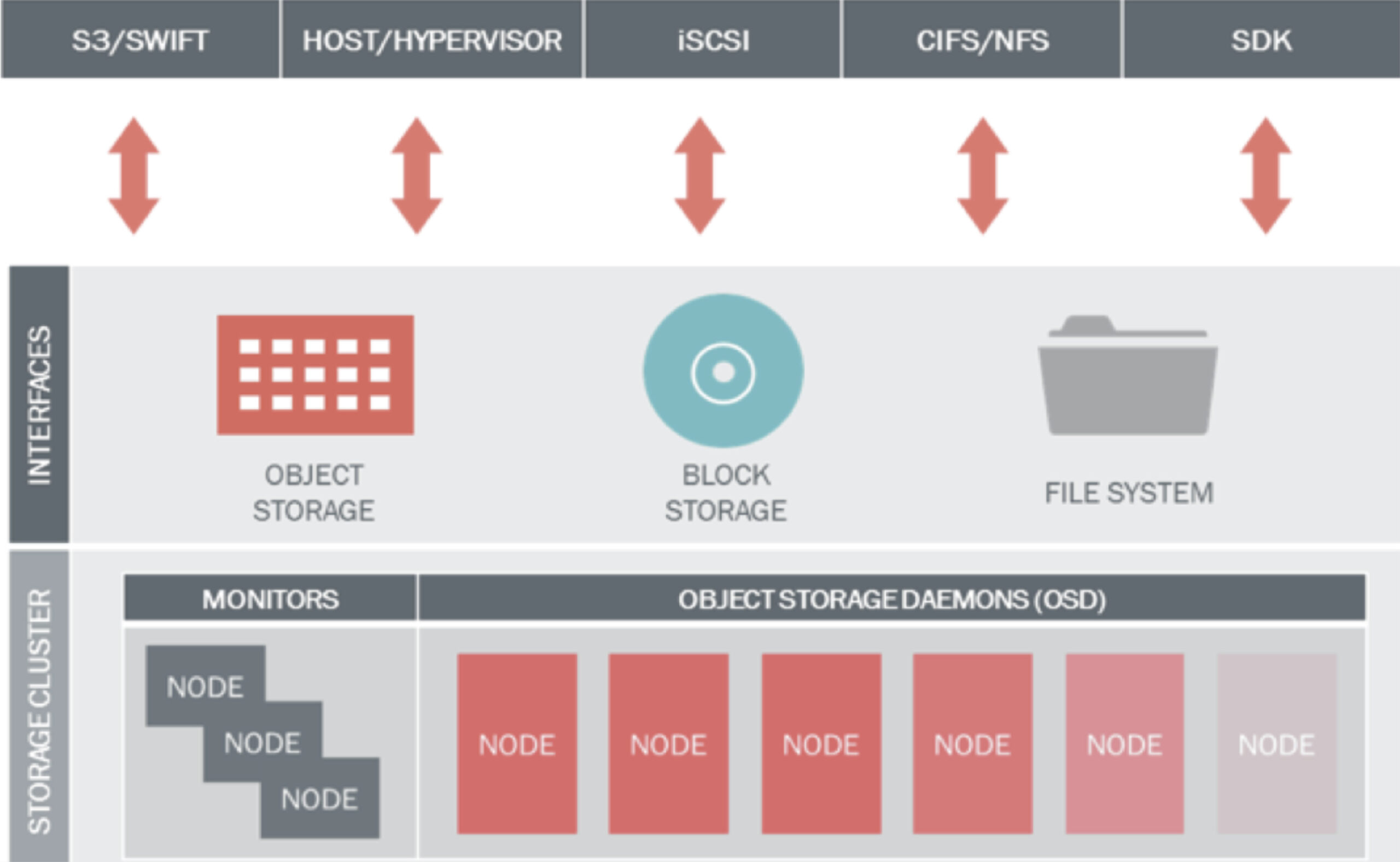
Ceph nesne tabanlı ve blok depolama ile dosya sistemi türündeki depolama ortamlarının tamamını bir arada sunan ve bu amaçla 5 temel bileşenden oluşan açık kaynak kodlu bir depolama çözümüdür. Bu 5 bileşen aşağıda açıklanmıştır:
- Ceph OSD (Object Storage Daemon): OSD bileşenleri veriyi nesne halinde tutmakla yükümlüdür. Verinin kopyalar halinde (replikasyon) tutulmasını yönetir. Disk ekleme/çıkarma işlemleri sonrasında verinin depolama ortamı üzerinde yeniden yapılandırılarak gerekli kopyaların oluşturulmasını ve diskler üzerinde dengeli olarak dağıtılmasını sağlar. Ayrıca monitör sunucularına disklerin durumu ile ilgili bilgi sağlar. Önerilen yapıda her disk için ayrı bir OSD kullanılması önemli konulardan birisidir.
- Ceph MON (Monitor): Monitör bileşenleri tüm depolama ortamının sağlıklı çalışmasını takip amacıyla haritasını tutar. MAP ismi verilen bu haritalar arasında OSD Map, Monitor Map, PG Map ve CRUSH Map bulunur. Monitör bileşenleri diğer tüm bileşenlerden durum bilgilerini alarak haritayı çıkarır ve bunu diğer monitör ve OSD bileşenleri ile paylaşır. Ceph istemcileri bir okuma veya yazma yapacağı zaman yazacağı OSD ve PG’leri belirledikten sonra bu OSD’lerin çalışır durumda olup olmadığına bakar. İlk belirlenen erişilebilir durumda değilse duruma göre 2. veya 3. OSD kullanılır. Burada belirlenen OSD sayısı replikasyon sayısına bağlıdır.
- Ceph RGW (Rados Gateway): RGW, Ceph’in doğrudan nesne tabanlı depolama ortamına erişmeye olanak veren API servisini sağlayan bileşendir. Bu API Amazon S3 ve OpenStack Swift API ile uyumludur.
- Ceph RBD (Rados Block Device): RBD, Ceph’in nesne tabanlı depolama altyapısı üzerinde çalışan ve sanal sunucular, fiziksel sunucular ve diğer istemcilere blok tabanlı depolama sağlayan katmanıdır. OpenStack ve CloudStack desteği bulunur. Ticari çözümlerin sunduğu snapshot, thin-provisioning ve compression gibi özellikleri destekler.
- Ceph FS (File System): Ceph’in nesne tabanlı depolama altyapısını kullanarak istemcilere POSIX uyumlu dosya sistemi vermesini sağlayan katmanıdır. Linux kernel üzerinde CephFS mount etmek üzere hali hazırda destek bulunduğu gibi alternatif olarak FUSE kullanılarak da mount işlemi yapılabilir. Diğer bileşenlerin aksine CephFS çalışmak için bir metadata sunucusuna ihtiyaç duyar.
Aşağıdaki resimde bu bileşenler gösterilmekte olup monitör sunucuları ve OSD sunucuları ile eğer ihtiyaç duyuluyorsa RGW sunucuları ve metadata sunucuları eklenerek aşağıdaki servisler sağlanabilir.
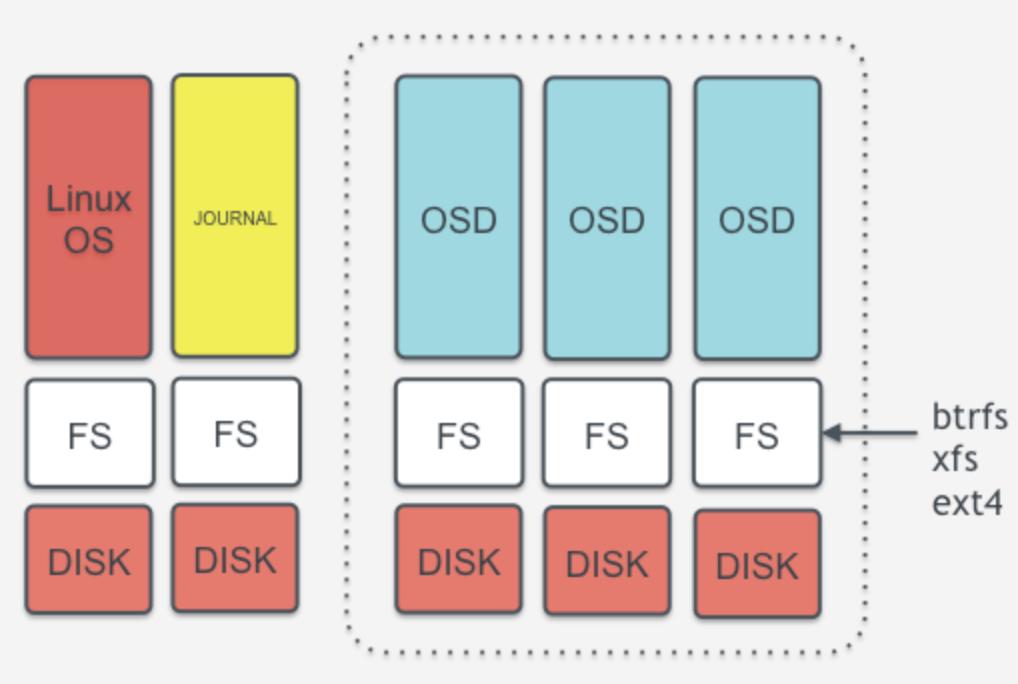
OSD katmanını biraz daha anlaşılabilir hale getirmek için aşağıdaki resimdeki yapıya dikkat çekilebilir. Depolamanın yapıldığı OSD sunucuları üzerinde işletim sisteminin çalıştığı bir disk ya da disk grubu bulunur. Bu resmin en solunda bulunan ilk sutünda görülmektedir. Alt katmandaki disk ext3, ext4, xfs gibi bir dosya sistemi ile formatlanarak üzerine işletim sistemi kurulur. Bu tüm sunuculardaki klasik kullanım şeklidir. Yanındaki sütunda sarı renk ile gösterilen journal ise OSD servislerinde çalışan mekanik disklere (SAS, SATA veya NL-SAS gibi) önbellek (cache) olarak bağlanmak üzere tasarlanan ve SSD üzerinde çalışan bir yapıdır. SSD disklerin yüksek yazma hızı ve IOPS performansından faydalanılarak yapılan yazma isteklerini karşılayarak sıralı (sequential) hale getirir. Bu disk üzerinde belirlenen süre boyunca önbelleklenen veri sıralı halde daha hızlı bir şekilde diske yazılır, böylece okunurken de sıralı biçimde daha hızlı okunur. OSD servislerine bağlı mekanik diskler ise resmin sağında yer alan ve kesikli çizgi ile çevrelenen alanda gösterilmektedir. Burada da diskler ext4, xfs veya btrfs gibi dosya sistemi ile formatlanarak OSD servislerine bağlanır. OSD servisi veriyi sunucu üzerine OSD servisleri ile mount edilen bu disklere nesneler halinde yazar.
Ceph Üzerinde Veri Yerleşimi
Ceph üzerindeki veri yerleşimini anlamak için önce Ceph tarafından kullanılan bazı temel yapı taşlarını anlamak gerekmektedir. Bunlardan bu aşamada gerekli olanlar aşağıda özetlenmiştir:
Veri Havuzu (Pool): Verileri birbirinden mantıksal olarak ayırmak üzere tasarlanmış, içerisinde imajları barındıran üst seviye bileşenlerdir. Her veri havuzu oluşturulurken veri miktarı ile doğru orantılı olarak belirlenen yerleşim grubu sayısı ile birlikte oluşturulur.
İmajlar (Images): Veri havuzlarının içerisinde yer alan ve blok depolama kullanmak üzere kullanılan bileşenlerdir.
Yerleşim Grubu (Placement Group-PG): Verileri gruplamak üzere OSD ve veri havuzları arasında kullanılan yapı taşlarıdır. OSD başına PG ortalamasının 100-150 civarı olması önerilmektedir. OSD başına PG sayısının 300’ü geçmesi sakıncalı bulunmaktadır.
Kural Grubu (Ruleset): Ceph’in kullandığı CRUSH algoritmasına ait haritanın (CRUSH Map) veriyi özel tanımlar ile hiyerarşik yapıda dağıtmasına izin vermek için kullandığı kurallardır. Varsayılan olarak hiyerarşik yapıda Region/DC/Room/Pod/PDU/Row/Rack/Chassis/Host/OSD olarak tanımlanan sırada örneğin farklı disk tiplerinden farklı veri havuzları oluşturarak (SSD’ler için ayrı, SAS’lar için ayrı, SATA’lar için ayrı) bu kurallar vasıtasıyla ilgili veri havuzlarının ilgili disk gruplarını kullanması sağlanır.
Buna göre herhangi bir istemci bir veri yazma talebinde bulunduğu zaman aşağıdaki resimdeki sıra ile yazılacak alan belirlenir ve replika sayısına göre kopya çıkarılır.
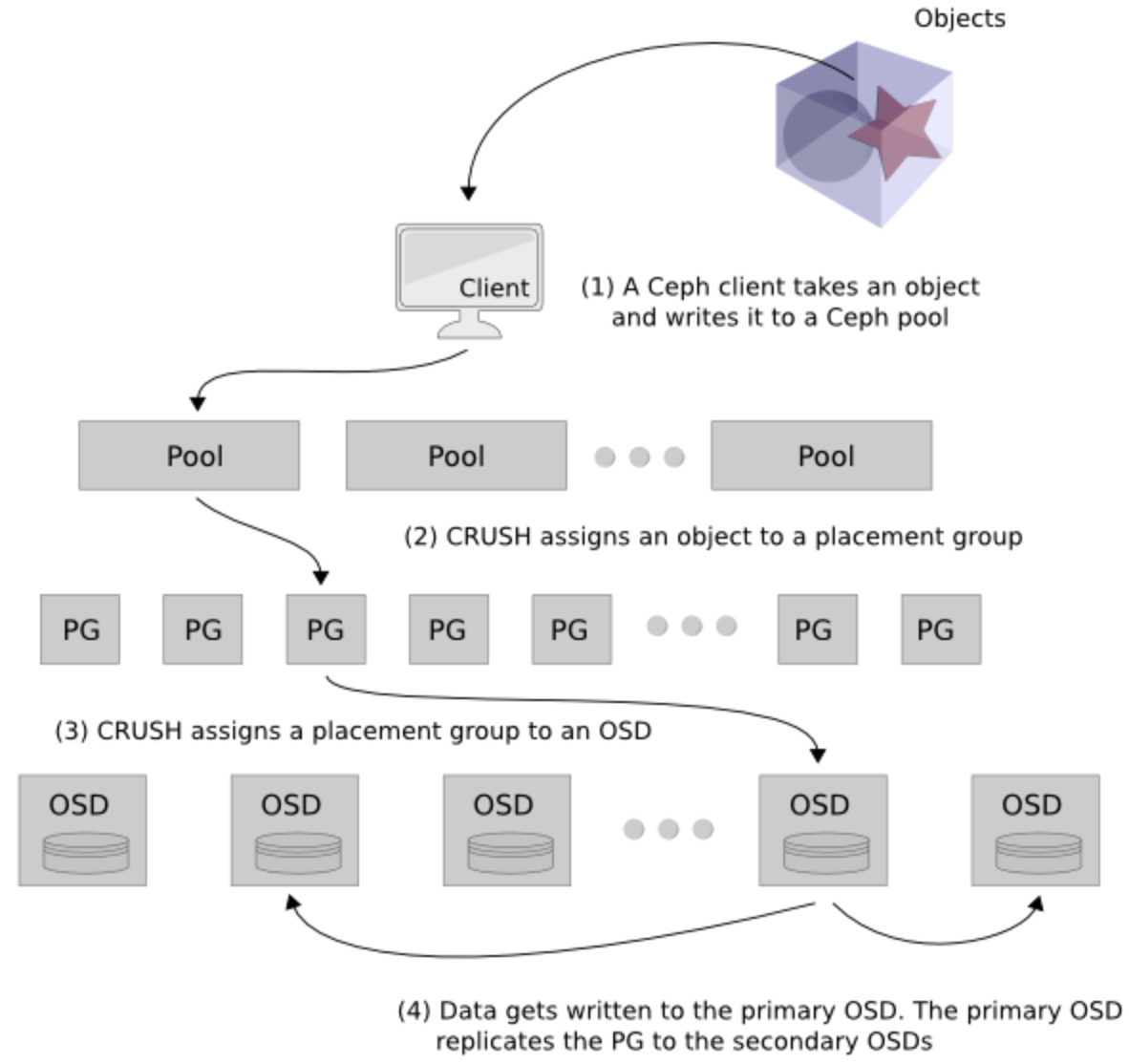
- Öncelikle istemci tarafından yazılacak veri belirlenir ve Ceph üzerinde bulunan bir veri havuzuna yazma talebi yapılır.
- CRUSH algoritması çalıştırılarak istemcinin yazması gereken PG ataması yapılır. Bu esnada herhangi bir metadata sunucusuna veya başka bir lookup tablosuna bakılmaz.
- CRUSH algoritması ayrıca kullanılacak PG’yi bir OSD ile eşler. Böylece istemci veriyi birincil olarak belirlenen PG dolayısıyla OSD üzerine yazar.
- CRUSH tarafından belirlenen birincil OSD’ye yazma işlemi tamamlanınca, verinin kopyası replika sayısına bağlı olarak diğer OSD’lere yazılır. Örneğin replika sayısı 3 ise birincil OSD’ye yazılan veri 2 ayrı OSD’ye daha kopyalanır. Bu OSD’ler varsayılan CRUSH map ayarlarında farklı sunucular üzerinde olacak şekilde ayarlanmıştır. Tüm kopyalar yazıldıktan sonra istemciye yazma işleminin başarılı olduğu bilgisi verilir.
CRUSH Algoritması
CRUSH (Controlled Replication Under Scalable Hashing), Ceph üzerinde verinin nereye yazılıp nereden okunacağını bir hesaplama yaparak belirleyen ve hem istemci hem de sunucularda bulunan, bu sayede veri lokasyonu için ikinci bir işlem gerektirmeyen bir algoritmadır. Daha önce bahsedildiği gibi Ceph bu yaklaşım sayesinde yüksek ölçeklere rahatlıkla çıkabilmektedir.
CRUSH map rolü ve sorumlulukları aşağıdaki gibidir:
- Her hiyerarşik yapı için tanımlanan kurallarla birlikte Ceph’in veriyi nasıl saklayacağını belirler.
- Çok aşamalı olabileceği gibi en az bir düğüm ve yaprak hiyerarşisine sahip olmalıdır.
- Hiyerarşideki her düğüm sepet (bucket) olarak adlandırılır ve her sepetin bir tipi vardır.
- Verileri tutan nesneler disklere verilebilecek ağırlıklara disklere dağıtılır.
- İhtiyaca göre istenilen esneklikte hiyerarşik yapı tanımlanabilir. Tek kısıt en alttaki yaprak ismi verilen düğümler OSD’leri temsil etmelidir. Ayrıca her yaprak düğüm bir sunucuya ya da başka bir tipteki sepete bağlı olmalıdır.
OSD ve PG Nedir ?
OSD Nedir ?
- Ceph Cluster’da her bir disk için bir ceph process’i koşmakta ve disk ile ilgili işlemleri yürütmektedir.
- Bu process’e Object Storage Daemon yani OSD denilmektedir.
- Genelde OSD ile bu process veya Ceph Cluster’ındaki her bir disk kast edilmektedir.
PG Nedir ?
- Placement Group’lar (PGs) Ceph client’ları tarafından görünmez fakat Ceph Cluster’larda önemli bir rol oynarlar.
- Bir Ceph Cluster’ı exabyte seviyesinde kapasiteye ulaştırmak için binlerce OSD eklemek gerekebilir.
- Ceph Client’lar objeleri pool lara kayıt ederler. Pool’lar tüm cluster’ın mantıksal alt kümeleri olarak düşünülebilir.
- Bir pool’daki toplam obje sayısı kolayca milyon ve üzeri sayılara çıkabilir.
- Milyonlarca veya daha fazla sayıda obje içeren bir sistemde hangi objenin nerede olduğunu obje bazlı takip etmek performans konusunda sıkıntılar çıkarır.
- Bu nedenle Ceph objeleri “Placement Group” lara ve Placement Group’ları da OSD’lere atar. Böylece hem verimlilik sağlar hem de dinamik bir şekilde objeleri yeniden dağıtabilir. (re-balancing)
- PG ve OSD ilişkisi aşağıdaki diagramlardan daha net anlaşılabilir.
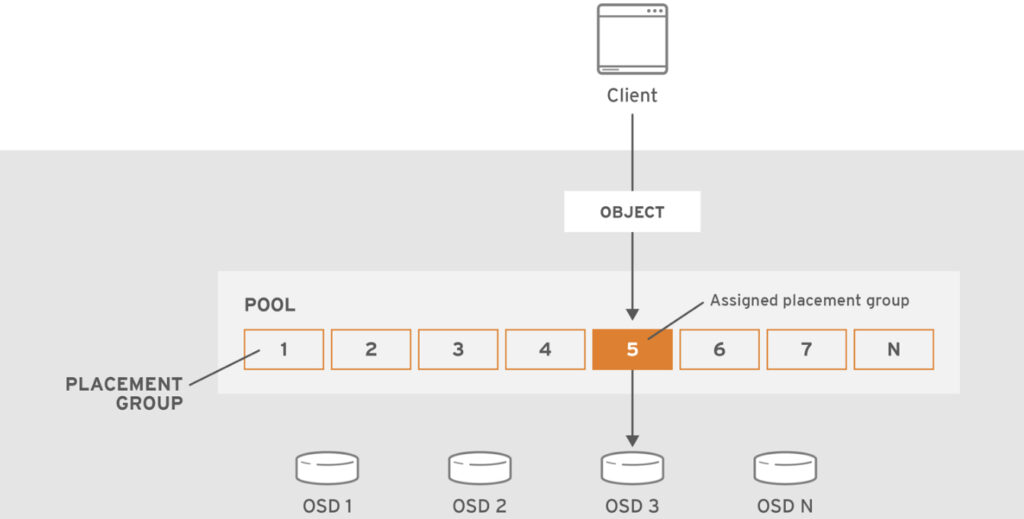
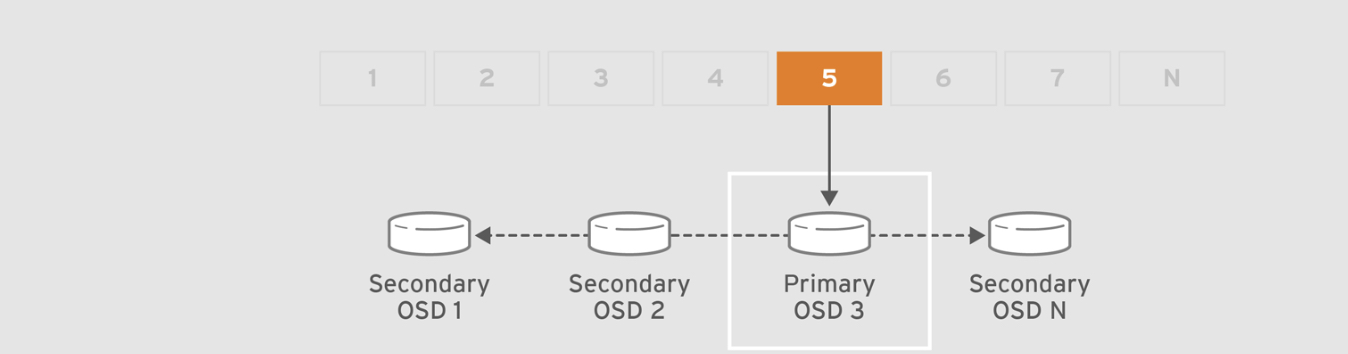
Ceph’de Placement Group’lar (PGs) hakkında detaylı bilgi için RedHat Ceph Dokümanında ilgili bölümü okuyabilirsiniz.
Dikkat !!!
- Ceph’de PG Sayısı artırma en önemli işlemlerden birisidir !
- Ceph’de PG artırma işlemi yavaş ve önerilen yöntemlerle yapılmazsa çok önemli performans sorunlarına yol açabilir.
- PGP_NUM artırma işlemi sonrası veri PG’ler arası taşınmaya başlar ve bu işlem durdurulamaz, geriye alınamaz ve bu işlemin bitmesi beklenmelidir.
- PG artırma işlemi cluster’ın az yoğun kullanıldığı saatlerde yapılmalıdır.
- İşlem sırasında kullanıcılar yaşanabilecek potansiyel performans etkileri konusunda bilgilendirilmelidir!
- İşlem yapılmadan önce daha yeni dokümanlar da incelenmelidir.
PG Sayısının Önemi
Ceph Cluster’ da Placement Group (PG) sayısı performans ve veri dağıtımı için çok kritik öneme sahiptir. Optimum değerleri bulmak için PG Hesap Makinesi kullanılmalıdır.
PG Hesap Makinesinde detaylı olarak da görülebileceği üzere Ceph’ de OSD başına 100 ile 300 arası PG tavsiye edilmektedir.
Ceph’de yeni bir pool oluştururken pool başına düşen PG (Placement Group) sayısını belirtebiliyoruz.
PG Sayısı ne zaman artırılmalı ? Performans ve veri sağlamlığını sağlamak için PG sayısını artırmamız gereken durumlar:
- Zaman içerisinde cluster’ımıza yeni OSD’ler eklediysek, OSD başına düşen PG miktarı 100 ve altına düştüyse
- PG sayısı ilk cluster kurulumunda yanlış belirlendiyse
PG artırma işlemi çok önemli olduğu için yükseltme yapmadan önce dikkatli planlama yapılmalı ve yakın öngürülebilir gelecekteki muhtemel cluster büyümeleri de hesaba katılmalıdır.
Eklenen her bir PG için OSD Node’ları ve Monitor Node’larının kaynak tüketimi (Memory, CPU, Network) artıyor, özellikle recovery işlemi sırasında bu kaynak tüketiminin daha da artacağı belirtiliyor.
PG sayısını minimum’da tutmak:
Kaynak tüketimini düşürüyor.
Verilerin dengesiz dağıtılmasına neden oluyor !
Ceph MGR Nedir ?
Depolama kullanımı, mevcut performans ölçümleri ve sistem yükü dahil olmak üzere çalışma zamanı ölçümlerini ve Ceph kümesinin mevcut durumunu takip etmekten sorumludur.
Ceph MON Nedir ?
MON map, Manager map, OSD map, MDS map ve CRUSH map dahil olmak üzere küme durumunun haritalarını tutar.
Bu haritalar, Ceph arka plan programlarının birbiriyle koordine olması için gerekli olan kritik küme durumudur.
Proxmox VE Ceph Storage Kurulumu
Artık Proxmox VE Ceph Storage kurulumuna başlayabiliriz.
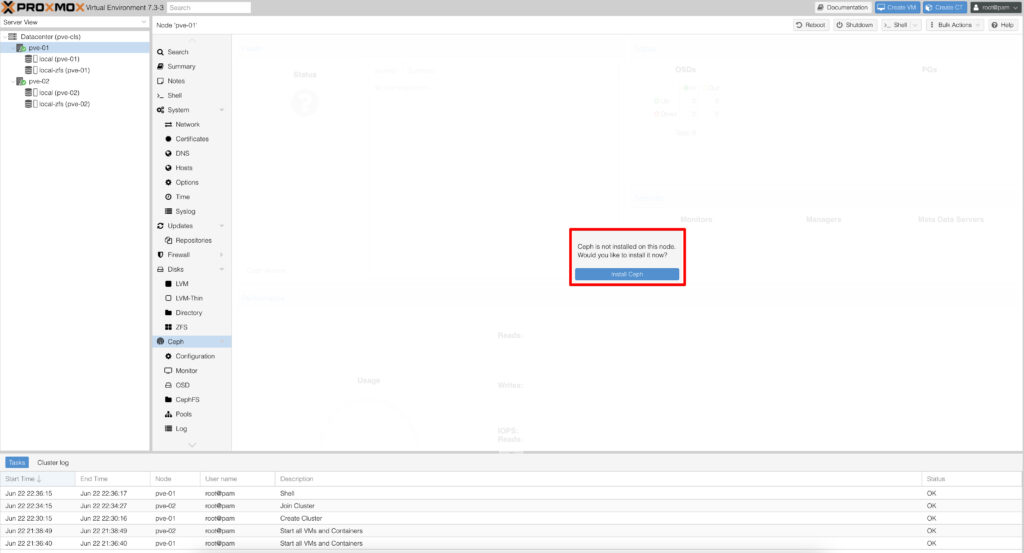
Kurup cluster oluşturduğumuz node’ lara Ceph Install yapmamız gerekiyor bunu ister GUI üzerinden isterseniz de cli üzerinden yapabilirsiniz. Ben kurulum sırasında GUI üzerinden ilerledik ama her adımda cli üzerinden de ilgili komut satırlarını yazacağım.
#pveceph install
Sonrasında kuracağımız sürümü burda tercih ediyoruz ama dikkat edilmesi gereken bir durum var Proxmox VE’ nin sürümü ile Ceph’in sürümün uyuşması gerekiyor. Ben yaptığım testlerde 17.2’nin quincy stabil çalışmadığını gördükten sonra 16.2 pacific versiyonunu kurduk.
Burada dikkat edilmesi gereken bir diğer konu ise community edition kullandığımız için Proxmox VE’nin community’ si üzerinden iki ürünün uyumunu sorgulamamız gerekiyor.
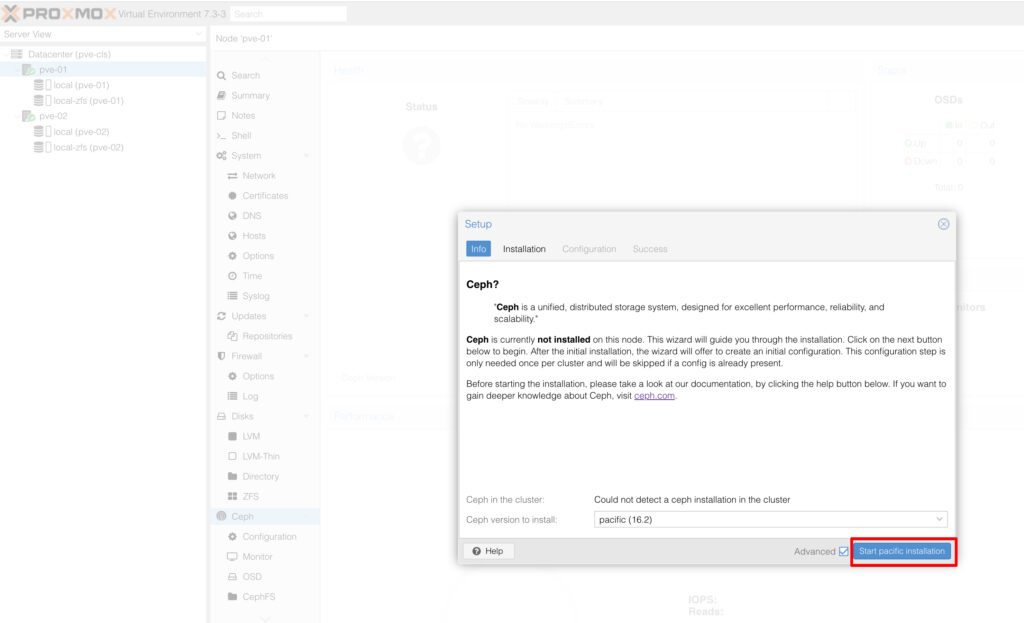
Next diyerek devam ediyoruz ve karşımıza cluster configuration ekranı gelecek burada ilk node’u seçiyoruz ve bunu Ceph Mon olarak seçiyoruz. Burada dikkat edilmesi gereken bir konu cluster network olacak, kurulumun ilerleyen adımlarında onuda cli üzerinden değiştireceğiz.
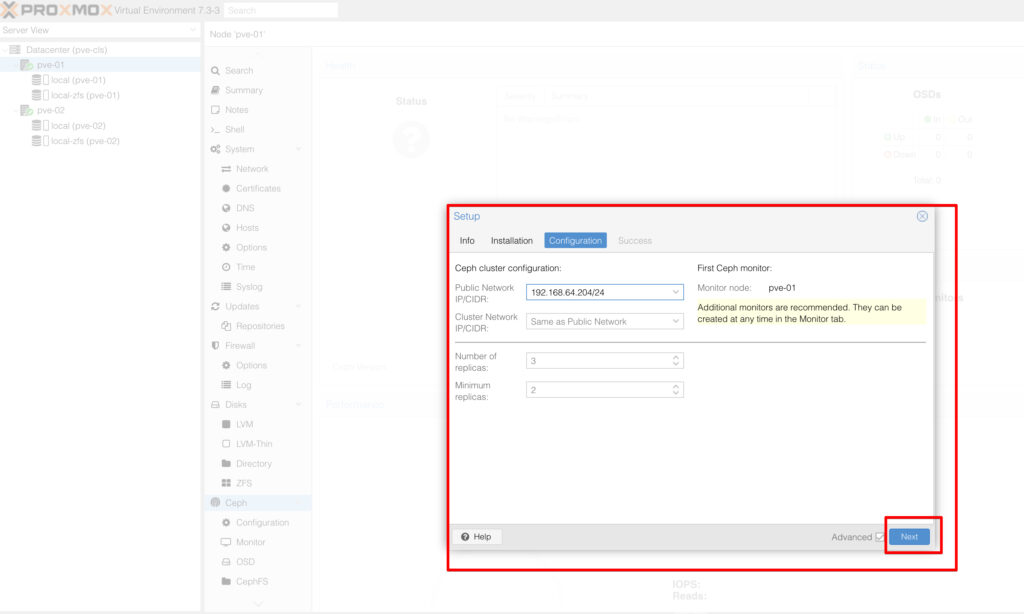
Burada network takımınız ile istişare ederek bond mimarisinde bir network config’i ile cluster network’ünüzü ayrı bir vlan ile ayırabilirsiniz.
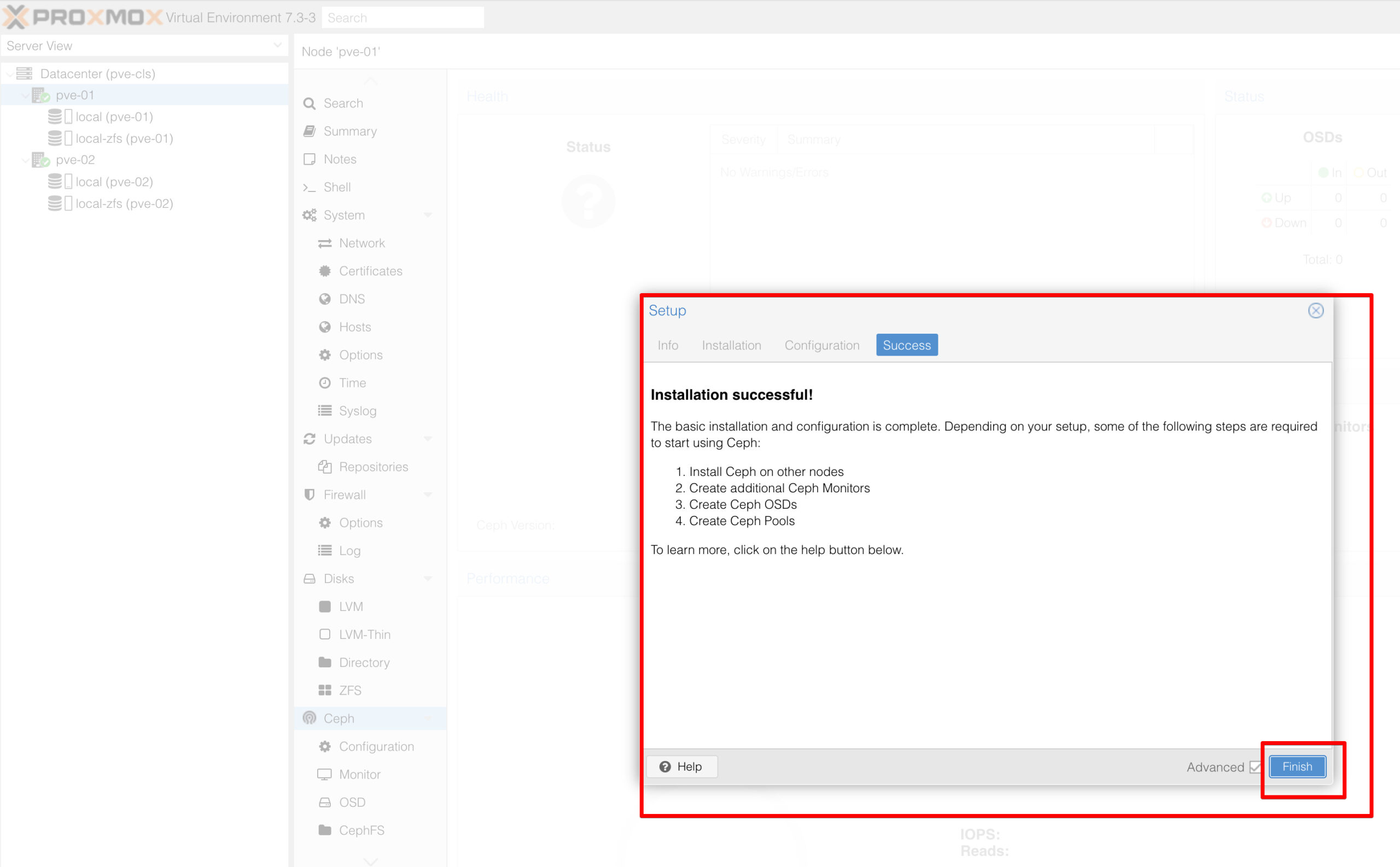
İlk node kurulumumuz tamamlandı sonrasında diğer node’larada ceph install işlemini yapıyoruz. Zatan burada kurulumlarla birlikte her node’un ceph mon‘u gelecektir. Biz daha sonrasında ceph mgr’ leri diğer node’ lara kuracağız.
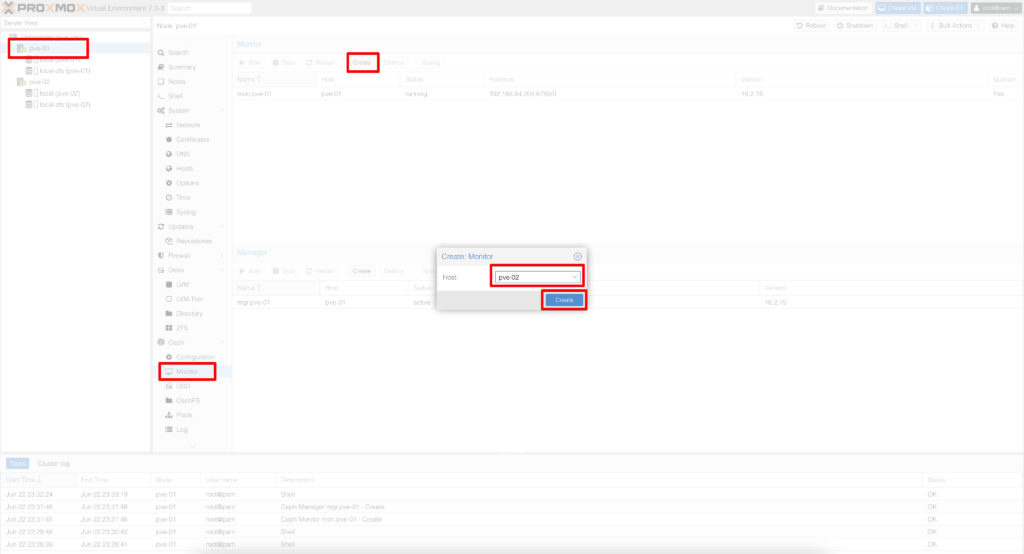
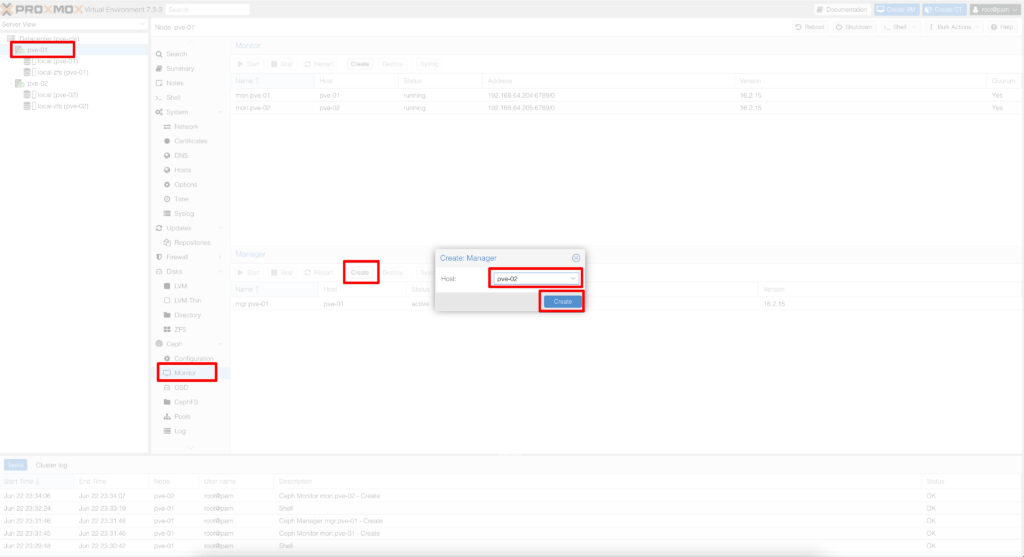
CLI üzerindende aşağıdaki komutlarla kurulumlarınızı yapabilirsiniz.
#pveceph createmon
#pveceph createmgr
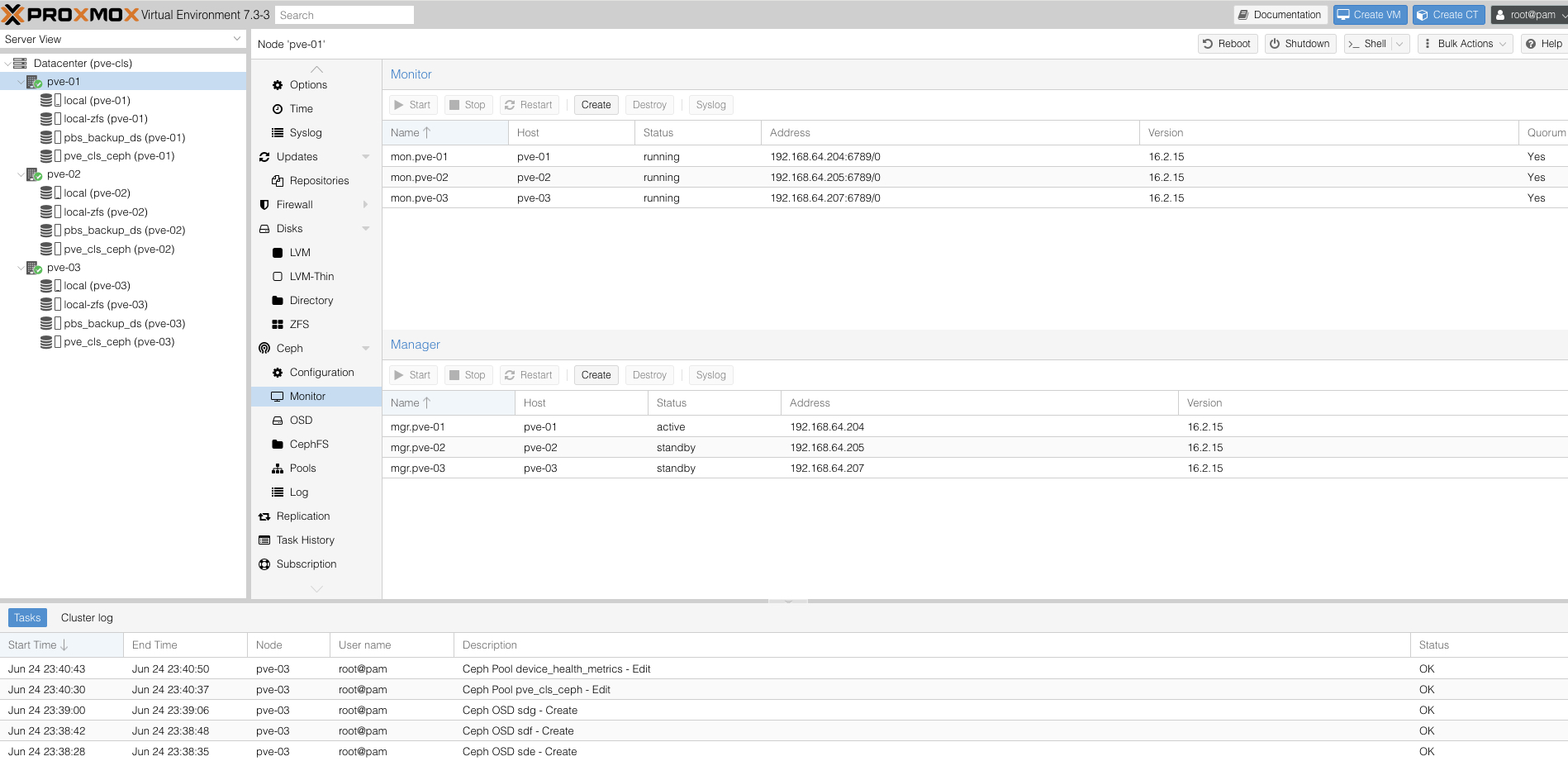
Ceph Install işlemimiz tamamlandı, ceph mon‘lar kuruldu ve ceph mgr‘ler kuruldu.
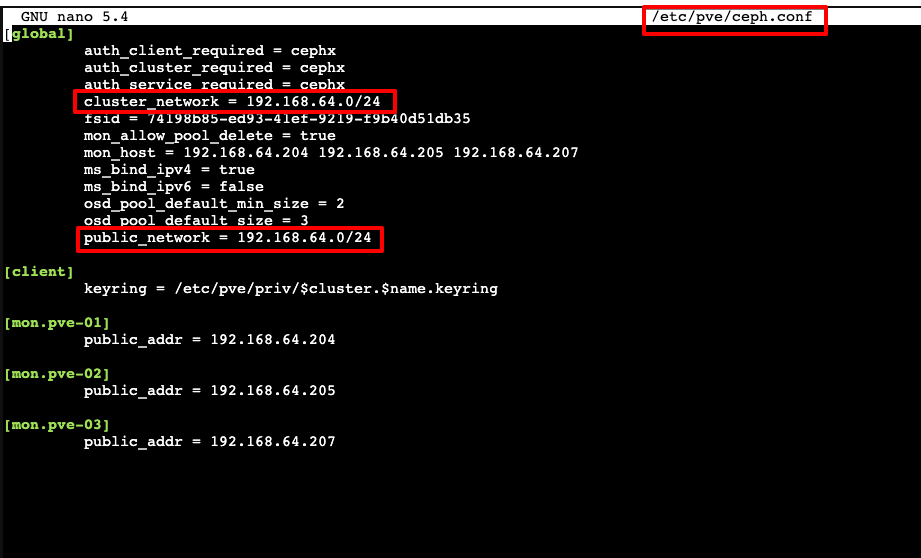
Burada yapmamız gereken bir diğer şey yazının içinde bahşetmiş olduğumuz cluster_network ve public_network düzeltilmesi olacak.
İlgili resimde ip’ler ilk node’a kurmuş olduğumuz ip ile geliyor biz bunları ilgili ip bloğu olarak değiştireceğiz.
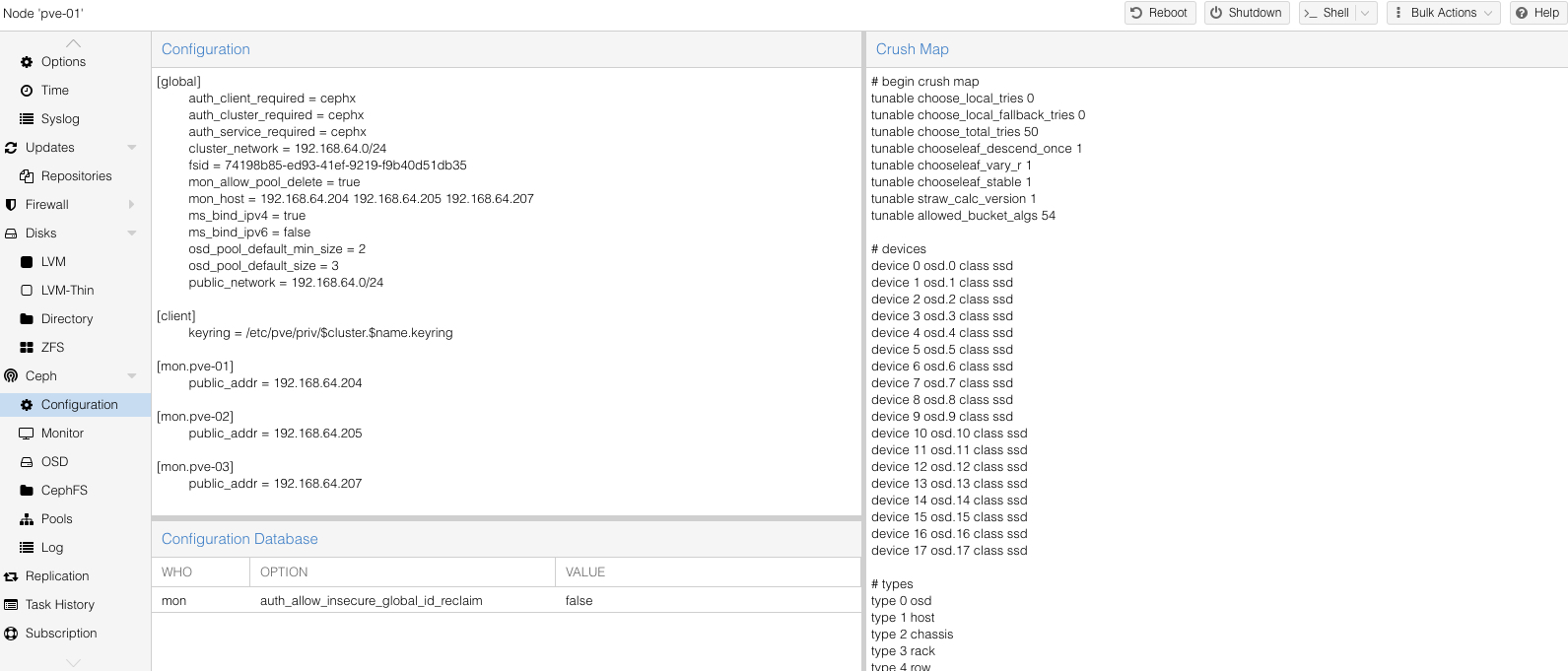
nano etc/pve/ceph.conf
Artık disklerimizi OSD olarak ayarlayabiliriz. Diğer adımlarda yapmış olduğumuz üzere burada da hem GUI üzerinden hemde cli üzerindenişlem yapma imkanımız bulunuyor. Node üzerindeki diskleri tek tek OSD olarak grupluyoruz.
#pveceph osd create /dev/sd[X]
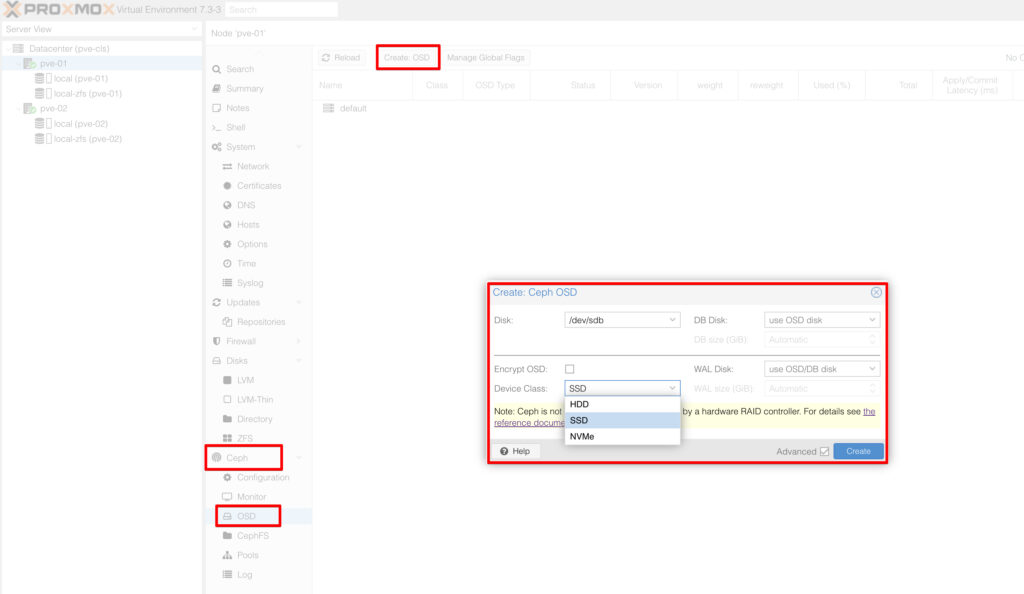
Aşağıdaki resimde görüldüğü gibi 3 node’lu bir Proxmox VE Cluster‘da 6’şar adet diskimizi her node üzerinde OSD olarak ayarladık.
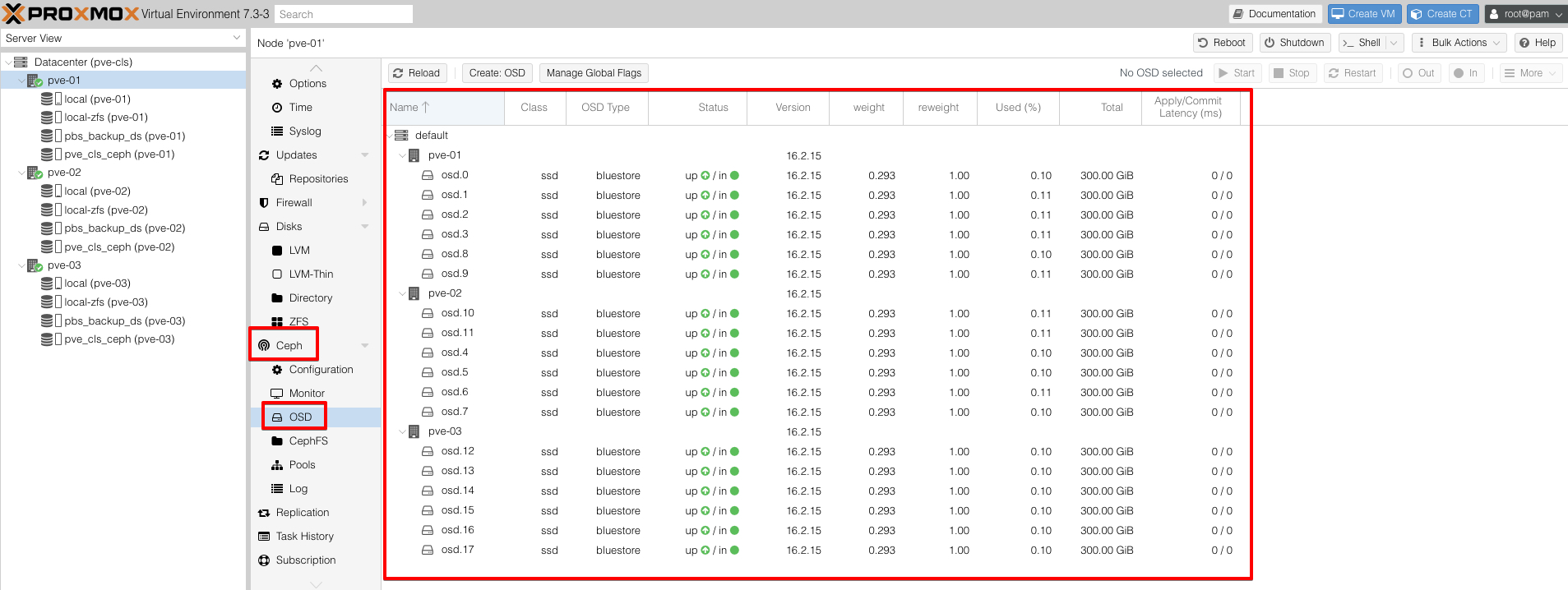
Son olarak 3 node’ da oluşturmuş olduğum OSD‘leri bir pool altında toplamaya.
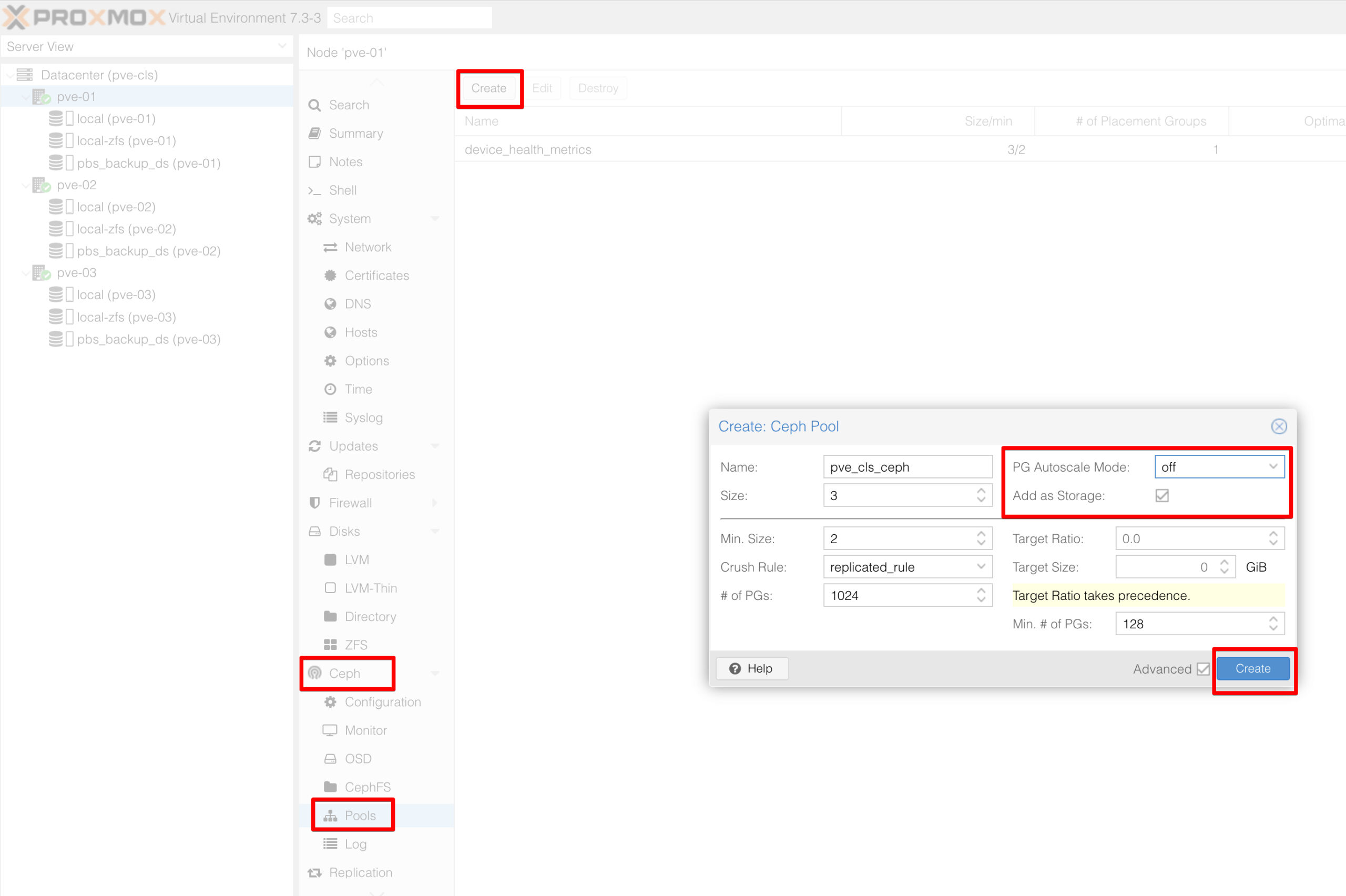
Create Ceph Pool diyerek karşımıza gelen ekran da pool’ umuza bir isim veriyoruz, replication size’ı “3“, minimum kopya sayısınıda “2” olarak bırakıyoruz.
Burada dikkat edilmesi gereken bir konu ise “PG Autoscale Mode” bunun “0ff” durumda olması gerekiyor neden diyecek olursanız yazımızın ilk bölümlerinde bahsetmiştik “PG” sayısının düşürülmesi yada yükseltilmesi kritik olduğundan dolayı bunu “On” bırakmamamız gerekiyor.
Son olarak gelelim “Number of PGs” ve “Min. Number of PGs” ayarlarına. Burada dikkatli davranmalıyız ve hesap yapmalıyız. Zatan “PG” sayısını ayarlarken mutlaka 2 ve katları olacak şekilde ayarlamalıyız.
Bizim ortamımız için yapılan hesaplamada ortam da 3 node var ve her node da 6 disk var buda 3×6 yaptığımızda 18 OSD ediyor. Replication size’ı “3” olarak düşündüğümüzde her OSD‘ye 128 PG veriyoruz zaten PG sayıları 100 ile 300 aralığında olmalıdır. 128 PG x 6 disk yaptığımızda node başına 768 PG oluyor bunu cluster olarak hesap ettiğimizde 768 PG x 3 node 2304 PG ediyor. Bunuda 3 replication size’a böldüğümüzde sayı 768 PG olarak karşımıza geliyor ama ileriye dönük büyümeyide düşünerek +1 fazlasını veriyorum ve number of PGs sayısını 1024 yapıyorum.
Yani minumum PGs 128 number of PGs ise 1024 olarak ayarlanıyor.
Tüm hesaplarda tamamlanınca bu pool’u storage olarak ekleyeceğiz. Add as Storage tikini işaretliyoruz.
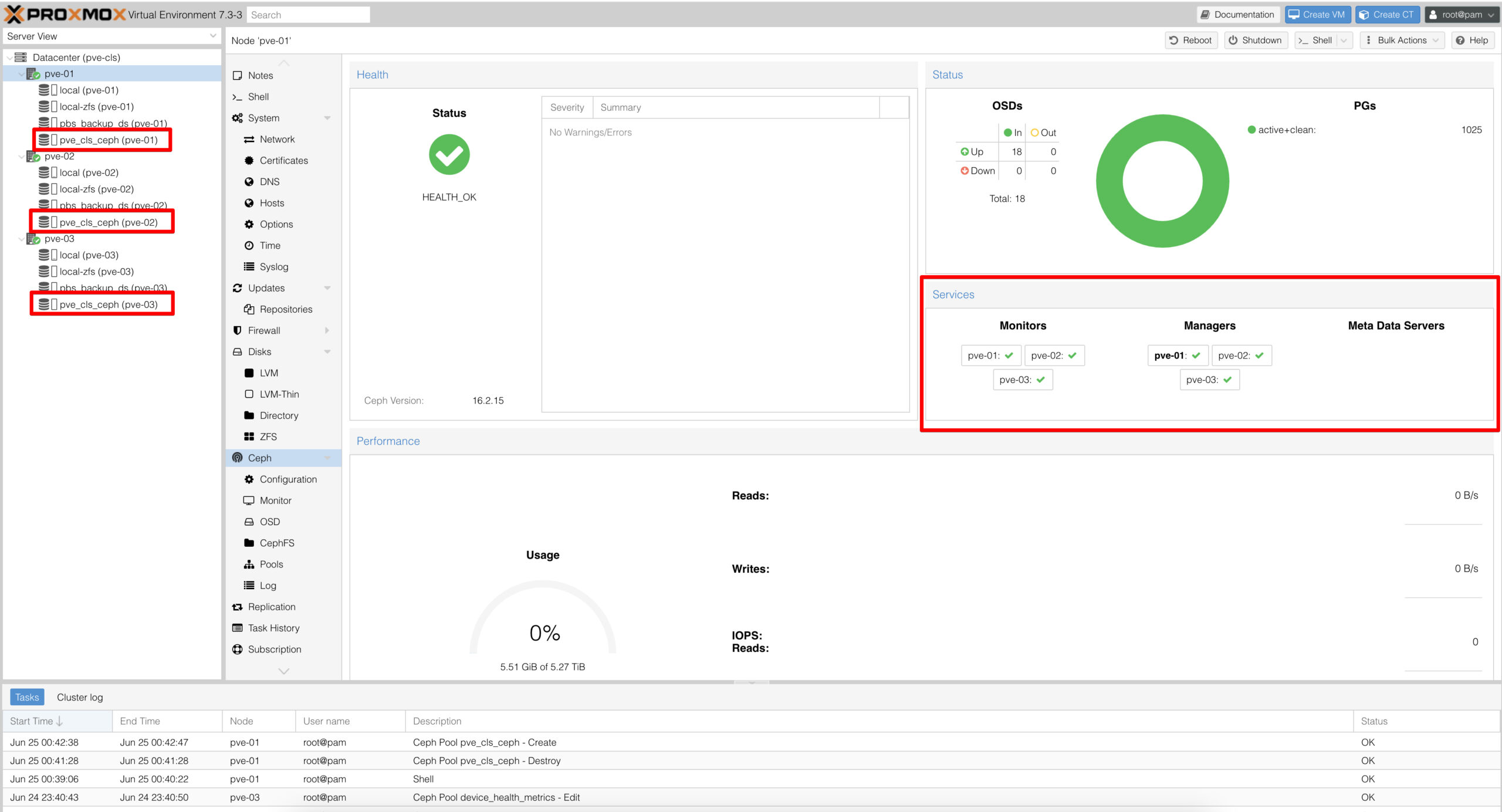
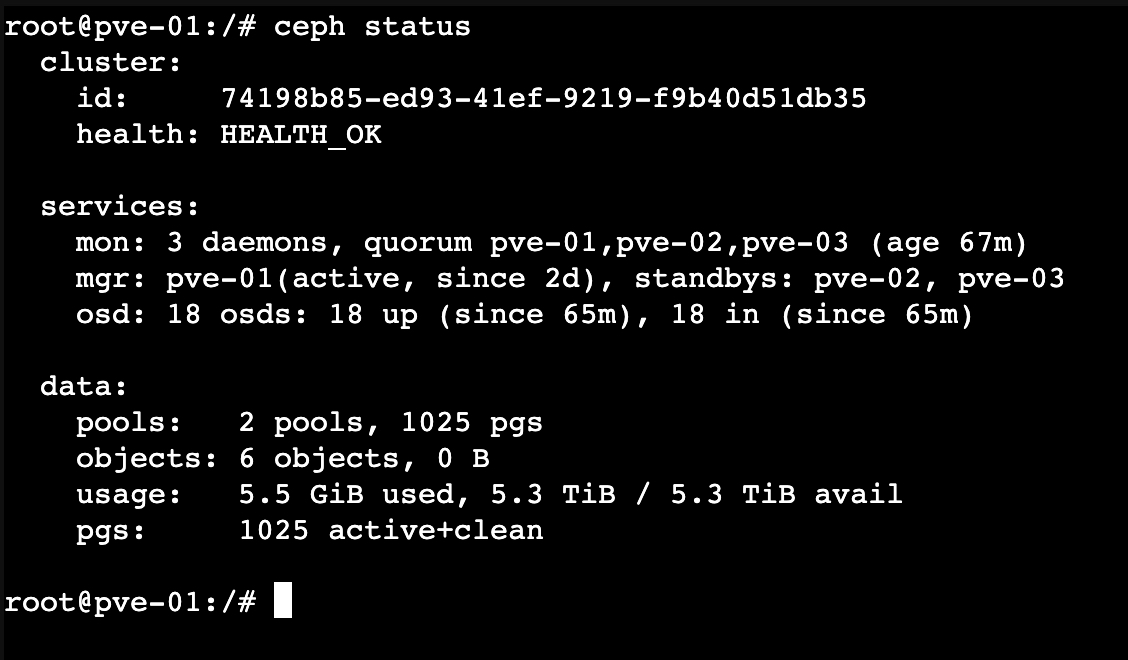
Ceph Cluster’ın status durumunu kontrol etmek için herhangi bir node’a cli üzerinden bağlanıp “ceph status” komutunu çalıştırıyoruz.
Ceph mimarisi tarafında desteklerini esirgemeyen mesai arkadaşlarım Yusuf Güngör ve Mesut Şahin‘e ayrıca teşekkür ederim.
Bir sonraki Proxmox yazımızda görüşmek üzere. Faydalı olması dileğiyle.